- A+
循环链表与普通的链表差不多
不同的是普通链表的最后一个结点的next为null
而循环链表的最后一个结点的next为链表的头结点
这样子就将链表头尾相连了
形成一个环
|
1 2 3 4 5 6 7 8 9 10 11 |
//循环链表的实现 class CycleLink<T> { public class Node { public T data; public Node next; } //定义一个指向尾结点的引用 private Node _last; private int _currentLenth = 0; |
这里同样的抽象一个类为数据结点
声明一个记录链表长度的变量
不同的是这里直接声明一个用于保存链表最后结点的引用
为什么不是头结点呢
因为循环只要用最后结点就可以轻松找到头结点了啊
|
1 2 3 4 5 6 7 8 |
public CycleLink() { //新建头结点 Node head = new Node(); _last = head; _last.next = head; } |
这里是循环链表的构造函数
循环链表的空链表表示方式就是
最后结点为头结点,并且next指向自身
这里就是初始化链表为这么一种情况
①新建一个结点为头结点
②使它当做为最后一个结点
③并使它的下一个结点next赋值为自身
|
1 2 3 4 5 6 7 8 9 10 |
//在循环链表尾部添加结点 public bool Add(T element) { Node addNode = new Node(); addNode.data = element; addNode.next = this._last.next; this._last.next = addNode; this._last = addNode; this._currentLenth++; return true; } |
在尾部添加元素
其实这里没什么好说的了
①新建一个新的结点
②赋值数据,赋值下一个结点为原最后结点的下一个结点(头结点)
③指定当前最后结点的下一结点为新加结点
④指定最后结点为新加结点
⑤链表的长度+1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//在循环链表头部添加结点 public bool AddAtFrist(T element) { //获取到头结点 Node head = this._last.next; Node addNode = new Node(); addNode.data = element; addNode.next = head.next; head.next = addNode; if (head == this._last) { //为空链表时 this._last = addNode; } this._currentLenth++; return true; } |
在链表的头部添加结点
①通过已知的最后结点获取到头结点
②新建结点,赋值数据,指定下一个节点为头结点的下一个结点
③指定头结点的下一个节点为新加结点
④注意,如果是空链表时,新加的结点就是尾结点,这时候尾结点就改变了,要对尾结点的引用修改为新加结点
⑤链表长度+1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
//获取指定位置的结点 public Node GetNodeByIndex(int index) { if (index < 0 || index > this._currentLenth) { Console.WriteLine("索引非法!"); return null; } Node head = this._last.next; Node node = head; int i = 0; while (i != index && node.next != head) { i++; node = node.next; } //其实上面已经判断过索引的合法性了,这里是没必要的 //但是写出来可以更好的理解上面的循环 if (i < index) { Console.WriteLine("索引非法!"); return null; } return node; } |
这个方法已经说过很多次了
不在乎这一次了^_^
①第一步当然是判断一下结点索引的合法性啦,要不然都要到火星去了
②通过尾结点得到头结点来做尾结点的判断
③声明一个计数器i初始化为对应结点node的位置
④通过遍历找到index==i位置的结点node
⑤最后当然就是返回这个结点了(注意这里0为头结点)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//获取指定位置的结点数据 public bool GetElement(int index,ref T element){ if (index == 0) { Console.WriteLine("头结点时没有数据的!"); return false; } Node node = this.GetNodeByIndex(index); if (node == null) { return false; } element = node.data; return true; } |
这个就不说了
排除头结点的特殊情况
直接获取到指定位置的结点取出数据就好
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//在循环链表指定位置插入结点 public bool Insert(int index,T element) { Node preNode = this.GetNodeByIndex(index - 1); if (preNode == null || preNode.next == this._last.next) { Console.WriteLine("插入位置的结点不存在!"); return false; } Node addNode = new Node(); addNode.data = element; addNode.next = preNode.next; preNode.next = addNode; this._currentLenth++; return true; } |
在指定位置插入新结点
可以去看看普通链表的图解
①先获取要插入结点的前一个结点
②判断结点和被插入结点是否存在,
这里preNode.next == this._last.next表示preNode是
链表中的最后一个结点
则可以证明被插入的结点就不存在了
③排除了意外,就新建结点,赋值数据,指定next下一个结点为被插节点
④指定被插结点的上一个结点的下一个结点为新建结点
(插入操作是不会修改尾结点的,因为被插元素要存在,而且被插结点永远在后面)
⑤链表的长度+1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
//删除指定位置的结点 public bool Delete(int index, ref T element) { Node preNode = this.GetNodeByIndex(index - 1); if (preNode == null || preNode.next == this._last.next) { Console.WriteLine("要删除的结点不存在!"); return false; } Node deleteNode = preNode.next; if (deleteNode == this._last) { this._last = preNode; } element = deleteNode.data; preNode.next = deleteNode.next; deleteNode = null; this._currentLenth--; return true; } |
这里同样的可以去看普通链表的图解
原理是一样的
我就不多说了
这里需要注意的就是要删除最后一个元素了
if(deleteNode == this._last)
如果将最后的结点删除了
那么最后结点的引用就要修改为被删结点(当前尾结点)的上一个结点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//通过某个节点遍历整个链表 public void CycleLinkByNode(Node node) { Node goNode = node.next; if(node != this._last.next){ Console.Write(node.data.ToString() + " "); } while (goNode != node) { if(goNode != this._last.next) Console.Write(goNode.data.ToString()+ " "); goNode = goNode.next; } } |
通过某个结点遍历整个链表
循环链表就是有这么一个功能
他可以用任意一个结点就可以遍历整个链表了
这里需要注意的就是特殊的头结点
它是没有数据的,所以要排除这个头结点
其他的从这个结点遍历到这个结点的前一个就好啦
测试
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
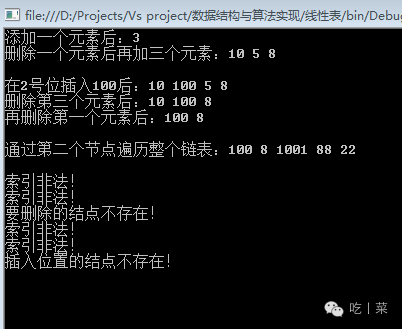
static void TestCycleLink() { //添加测试 int element = 0; CycleLink<int> c = new CycleLink<int>(); c.Add(3); PrintCycleLink(c, "添加一个元素后:"); c.Delete(1, ref element); c.AddAtFrist(5); c.Add(8); c.AddAtFrist(10); PrintCycleLink(c, "删除一个元素后再加三个元素:"); Console.WriteLine(); //插入和删除 c.Insert(2, 100); PrintCycleLink(c, "在2号位插入100后:"); c.Delete(3, ref element); PrintCycleLink(c, "删除第三个元素后:"); c.Delete(1, ref element); PrintCycleLink(c, "再删除第一个元素后:"); Console.WriteLine(); //通过一个节点遍历链表 c.Add(1001); c.AddAtFrist(22); c.Add(88); Console.Write("通过第二个节点遍历整个链表:"); c.CycleLinkByNode(c.GetNodeByIndex(2)); Console.WriteLine(); Console.WriteLine(); //索引测试 c.GetElement(-1, ref element); c.Delete(200, ref element); c.GetNodeByIndex(-2); c.Insert(20, 30); Console.WriteLine(); } static void PrintCycleLink(CycleLink<int> c, string text = "输出:") { Console.Write(text); c.CycleLinkByNode(c.GetNodeByIndex(0)); Console.WriteLine(); } |
结果
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//链接两条链表 public bool Connect(CycleLink<T> C) { Node head1 = this._last.next; //取添加的链表的第一个结点 Node first2 = C._last.next.next; this._last.next = first2; C._last.next = head1; this._currentLenth += C._currentLenth; this._last = C._last; return true; } |
链接两条链表
很明显的思路就是主链表的尾与添加链表的第一结点相连
添加链表的尾结点与主链表的头结点相连
这样又组成一条新的链表
①获取到主链表的头结点
②获取添加链表的第一个结点
③尾一相连,赋值给主链表尾结点的下一节点为添加链表的第一个结点
④尾头相连,赋值给添加链表尾结点的下一个结点为主链表的头结点
⑤链表的长度增加对应的长度
⑥设置主链表的尾结点添加链表的尾结点
测试
|
1 2 3 4 5 6 7 8 9 10 |
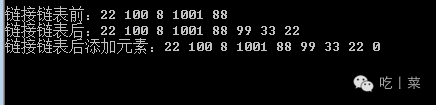
//测试链接两链表 CycleLink<int> c2 = new CycleLink<int>(); c2.Add(99); c2.Add(33); c2.Add(22); PrintCycleLink(c, "链接链表前:"); c.Connect(c2); PrintCycleLink(c, "链接链表后:"); c.Add(0); PrintCycleLink(c, "链接链表后添加元素:"); |
结果